


Spring Batch를 사용하면서 대용량 데이터를 일괄 처리할 때 발생하는 성능 이슈를 해결하는 방법에 대해서 이야기 해보고자 합니다.
전체 코드는 링크에서 확인하실 수 있습니다.
Batch 성능 개선이 필요한 이유
Spring Batch는 대량의 데이터를 효율적으로 처리할 수 있는 강력한 프레임워크지만 처리해야 할 데이터 양이 많을수록 성능 문제가 발생할 가능성이 커집니다.
예를 들어, Batch 작업 시간이 25만 번에 1시간이 걸린다면, 1억 번 처리 시에는 약 400시간이 소요될 것입니다. 이러한 시간 지연은 비즈니스에 심각한 영향을 미칠 수 있습니다.
성능 개선
배치 작업은 주로 세 가지 주요 구성 요소인 Reader, Processor, Writer로 나눌 수 있습니다. 이에 대한 성능 개선 방법에 대해 알아보겠습니다.
주의할 점은 자신이 배치를 사용하는 용도와 상황에 맞춰 방법을 선택하는 것이 중요합니다.
Reader 성능 개선
복잡한 조회 조건을 통해 데이터를 가져오기 때문에 대부분 배치에서 데이터를 읽는 Reader가 Writer보다 대체적으로 늦게 처리됩니다. 따라서 배치 성능 개선의 첫걸음은 Reader 개선이라고 볼 수 있습니다.
1. 커버링 인덱스 사용
-- create_date index
SELECT p.* FROM product p JOIN
(SELECT id FROM product WHERE create_date = :date ORDER BY id ASC LIMIT :page, :pageSize) as temp
on temp.id = p.id서브쿼리에서 커버링 인덱스를 사용하여 조건에 맞는 id 값들을 효율적으로 빠르게 추출하고, 메인 쿼리에서 조인 처리을 처리하고 있습니다. 서브쿼리에 커버링 인덱스가 적용되면서, 전체적인 쿼리 실행 시간이 단축됩니다.
커버링 인덱스(Covering Index)
데이터베이스에서 특정 쿼리를 처리할 때 필요한 모든 데이터를 인덱스에서 바로 가져올 수 있는 인덱스를 말합니다. 일반적으로 데이터베이스는 데이터를 찾기 위해 인덱스를 검색한 다음, 실제 데이터가 저장된 곳으로 이동하여 필요한 데이터를 가져옵니다. 하지만 커버링 인덱스를 사용하면 이 과정이 더 간단해집니다. 대신 인덱스의 용량이 증가하게 됩니다.
간단한 사용 예시 코드 보여드리겠습니다.
// JdbcTemplate Paging Reader
public class CustomJdbcPagingItemReader<T> implements ItemReader<T> {
private final NamedParameterJdbcTemplate jdbcTemplate;
private final String query;
private final RowMapper<T> rowMapper;
private int page;
private final int pageSize;
private int currentItemIndex;
private List<T> items;
private LocalDate date;
protected Log logger = LogFactory.getLog(getClass());
public CustomJdbcPagingItemReader(DataSource dataSource, String query, RowMapper<T> rowMapper, int pageSize) {
this.jdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
this.query = query;
this.rowMapper = rowMapper;
this.page = 0;
this.pageSize = pageSize;
this.currentItemIndex = 0;
}
public void setDate(LocalDate date) {
this.date = date;
}
@Override
public T read() {
if (items == null || currentItemIndex >= items.size()) {
fetchNextPage();
}
if (items == null || items.isEmpty()) {
return null; // 더 이상 읽을 데이터가 없음
}
return items.get(currentItemIndex++);
}
private void fetchNextPage() {
Map<String, Object> parameters = new HashMap<>();
parameters.put("page", page * pageSize);
parameters.put("pageSize", pageSize);
parameters.put("date", date);
items = jdbcTemplate.query(query, parameters, rowMapper);
currentItemIndex = 0;
page++;
}
}// Batch 작업
@JobScope
@Bean
public CustomJdbcPagingItemReader<Product> reader() {
String query = "SELECT p.* FROM product p JOIN (SELECT id FROM product WHERE create_date = :date ORDER BY id ASC LIMIT :page, :pageSize) as temp on temp.id = p.id";
CustomJdbcPagingItemReader<Product> reader = new CustomJdbcPagingItemReader<>(dataSource, query, new ProductRowMapper(), chunkSize);
reader.setDate(jobParameter.getDate());
return reader;
}2. OFFSET 성능 개선 사용
chunk단위로 처리할 때 보통 페이징 방식을 사용하는데 이때 MySQL은 LIMIT OFFSET을 사용합니다.
MySQL에서는 먼저 OFFSET 값만큼의 레코드를 건너뛴 후, 그 다음에 LIMIT 값만큼의 레코드를 가져옵니다. 예를 들어, LIMIT 10 OFFSET 1000이라는 쿼리는 처음 1000개의 레코드를 건너뛴 후 다음 10개의 레코드를 선택합니다. 그러다보니 시작할 레코드의 위치까지 모든 행을 건너뛰기 위해 데이터를 읽고 버려야합니다.
이러한 부분이 대량의 데이터가 있는 테이블에서 성능 저하의 주요 원인이 됩니다.
SELECT * FROM product WHERE create_date = ? ORDER BY id ASC limit 0, 100 -- 빠름
SELECT * FROM product WHERE create_date = ? ORDER BY id ASC limit 5000000, 100 -- OFFSET이 커질수록 느려짐이런 문제를 해결하기 위해 PK를 기준으로 데이터를 정렬하고 OFFSET을 0으로 유지하는 방법을 사용할 수 있습니다.
SELECT * FROM product WHERE create_date = ? AND id > 0 ORDER BY id ASC limit 0, 1000
SELECT * FROM product WHERE create_date = ? AND id > 5000001 ORDER BY id ASC limit 0, 10003. JdbcCursorItemReader 사용
Paging 방식이 아닌 JdbcCursorItemReader는 Cursor를 사용해 데이터가 없을 때까지 지속해서 데이터를 읽는 방식입니다.
@JobScope
@Bean
public JdbcCursorItemReader<Product> reader() {
return new JdbcCursorItemReaderBuilder<Product>()
.name("jdbcCursorItemReader")
.fetchSize(chunkSize)
.sql("SELECT * FROM product WHERE create_date = ? ORDER BY id ASC")
.rowMapper(new ProductRowMapper())
.dataSource(dataSource)
.preparedStatementSetter(ps -> ps.setDate(1, Date.valueOf(jobParameter.getDate())))
.build();
}주의: JpaCursorItemReader는 데이터를 모두 읽고 서버에서 직접 Cursor하는 방식이라 OOM(OutOfMemory)을 유발할 수 있습니다. JdbcCursorItemReader 사용을 권장합니다.
성능 비교
100만개 데이터를 대상으로 간단한 조건 쿼리(인덱스 사용)를 사용해서 테스트를 진행하였습니다.
| Reader | 총 소요시간 |
|---|---|
| QuerydslPagingItemReader | 25분 27초 |
| QuerydslZeroPagingItemReader | 14분 48초 |
| JdbcCursorItemReader | 14분 43초 |
| JdbcCoveringIndexPagingItemReader | 16분 20초 |
OFFSET을 개선한 QuerydslZeroPagingItemReader의 경우 끝날때 까지 일정한 읽기 속도를 보여줬습니다.
Processor 성능 개선
대규모 데이터를 다루는 통계 쿼리 작성시, 일반적으로 GROUP BY와 SUM을 활용합니다. 하지만 데이터 양이 증가하고 쿼리가 복잡해짐에 따라, 성능적으로 개선하기 힘들어지는 경우가 많습니다.
여러 테이블을 조인하고 GROUP BY 하는 것은 잘못된 쿼리 실행계획을 만들고 쿼리 튜닝도 어렵게 만듭니다.
복잡한 쿼리의 문제점
JOIN + GROUP BY + SUM의 조합을 사용하는 복잡한 쿼리는 다음과 같은 문제점을 안고 있습니다.
-
데이터베이스 부하 증가: 복잡한 계산과 대량의 데이터 처리는 데이터베이스에 상당한 부하를 야기할 수 있습니다.
-
쿼리 실행 계획 및 튜닝의 어려움: 복잡한 쿼리는 성능과 관련된 실행 계획의 민감도를 증가시켜, 최적화와 튜닝 과정을 복잡하게 만듭니다.
Redis 파이프라인 사용
GROUP BY를 배제하고, 직접적인 집계(Aggregation) 방식을 채택하여 쿼리를 단순화시키는 것으로 성능을 향상 시킬 수 있습니다. 이때, 어플리케이션에서 직접적인 데이터 처리는 OOM(Out Of Memory)이 발생할 수 있어 충분한 메모리와 빠른 연산을 수행하는 Redis를 활용할 수 있습니다.
주의할 점은 Redis를 사용할 때 각 데이터 항목(item)을 처리하며 발생하는 네트워크 I/O가 전체 성능에 영향을 줄 수 있다는 것입니다. Redis 명령은 기본적으로 각 항목을 처리할 때마다 개별적으로 실행되며, 이로 인해 네트워크 I/O가 증가하게 됩니다. 네트워크 I/O가 많아지면 전체적인 응답 시간이 느려지고, 결과적으로는 성능이 저하될 수 있습니다.
Redis 파이프라인을 사용하면 파이프라인을 통해 여러 Redis 명령을 그룹화하고, 이들을 단일 네트워크 요청으로 묶어 처리함으로써 네트워크 I/O를 줄일 수 있습니다. 예를 들어, 천만 개의 합산 연산을 파이프라인을 통해 처리한다면, 천만 번의 네트워크 I/O 대신 청크 단위로 나누어진 적은 수의 네트워크 I/O로 처리가 가능해집니다.
추가로 Spring Data Redis에서는 이 기능을 직접적으로 지원하지 않으므로, Redis 파이프라인을 위한 별도의 대량 처리 라이브러리 개발이 필요합니다.
@Bean
public ItemWriter<Product> redisItemWriter() {
return products -> stringRedisTemplate.executePipelined((RedisCallback<Object>) connection -> {
for (Product product : products) {
String key = redisKeyPrefix + product.getCreateDate().toString();
connection.stringCommands().incrBy(key.getBytes(), product.getAmount());
}
return null;
});
}
@Bean
public StepExecutionListener redisToDatabaseSaver() {
return new StepExecutionListener() {
@Override
public ExitStatus afterStep(@NonNull StepExecution stepExecution) {
EntityManager entityManager = entityManagerFactory.createEntityManager();
EntityTransaction transaction = entityManager.getTransaction();
transaction.begin();
try {
Set<String> keys = redisTemplate.keys(redisKeyPrefix + "*");
ValueOperations<String, Long> valueOps = redisTemplate.opsForValue();
for (String key : keys) {
Long totalAmount = valueOps.get(key);
LocalDate createDate = LocalDate.parse(key.split(":")[1]);
ProductBackup backup = ProductBackup.builder()
.amount(totalAmount)
.createDate(createDate)
.build();
entityManager.merge(backup);
}
transaction.commit();
} catch (Exception e) {
transaction.rollback();
throw e;
} finally {
entityManager.close();
}
return ExitStatus.COMPLETED;
}
};
}파이프라인 사용 전 후 성능 비교
100만개의 데이터를 대상으로 간단한 SUM 쿼리를 통해 PipeLine 사용 전 후 성능을 비교하였습니다.
| 처리 방법 | 총 소요시간 |
|---|---|
| Redis | 11분 11초 |
| Redis PipeLine | 48초 |
Processor에서 API 사용시 느린 경우
Spring Batch의 Processor는 기본적으로 단건 처리를 기반으로 설계되어 있습니다. 각 데이터 항목을 독립적으로 처리할 수 있는 장점이 있지만, API 호출과 같은 네트워크 I/O 작업을 포함할 경우 성능 저하의 원인이 됩니다.
Processor에서 회원 정보를 조회하는 API가 150ms가 걸리고 chunk 사이즈가 1000이라면 150,000ms(약 2.5분)이 소요됩니다.
벌크 API로 변경
API 자체를 단건 조회 대신 한번에 여러 항목을 한 번에 조회할 수 있는 벌크 API를 제공하도록 하여 성능을 개선할 수 있습니다.
Writer 처리로 변경
API 스펙이 변경이 불가능한 경우, Processor 제거하고 대신 Writer에서 네트워크 I/O 작업을 수행하는 방법이 있습니다.
RX 기반 멀티 스레드 Writer 처리
Reader에서 Item을 단건이 아닌 Chunk Size만큼 List로 넘겨받는 Writer 단계에서 RX(Reactive Extensions)를 활용한 멀티 스레드 방식으로 네트워크 I/O 작업을 병렬 처리하여 성능을 개선할 수 있습니다.
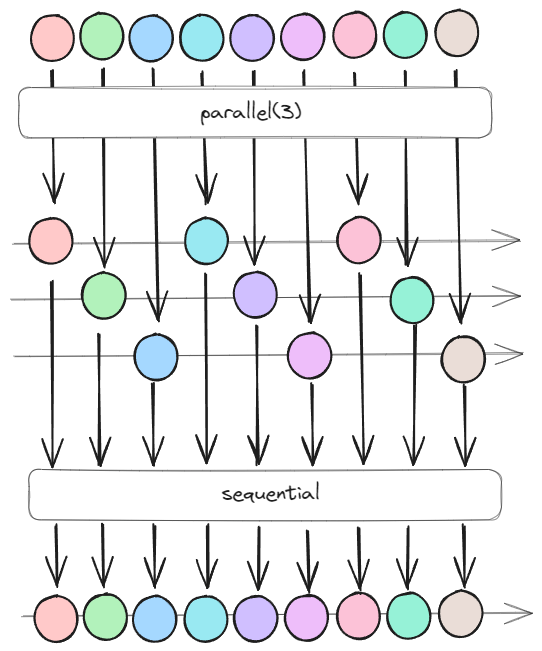
그림을 보면 다른 데이터 항목들이 병렬적으로 처리되고 있는데 parallel(3)은 동시에 세 개의 작업을 처리할 수 있는 병렬 처리 능력을 의미합니다. 병렬 처리된 데이터 스트림은 sequential 프로세스를 통해 순차적으로 병합되고 이후 추가적인 INSERT나 UPDATE를 진행하게 됩니다.
주의할 점은 병렬 처리(parallel) 숫자를 무한정으로 늘린다고 빨라지지 않는다는 점입니다. 나누고 병합하는 과정에서 추가적인 리소스가 들어가고 DB 커넥션수와 CPU 리소스를 고려해야합니다. 스케줄 I/O 시스템 내부적으로 지정해주는 값을 사용하는 것도 좋은 방법입니다.
Writer 성능 개선
Writer에서는 데이터베이스 I/O를 최소화 하는 방법으로 성능을 개선할 수 있습니다.
배치 삽입(Batch Insert) 활용
네트워크 지연(latency)이 성능 저하의 주요 원인이 될 수 있으며, 이를 최소화하기 위해 쿼리를 일괄적으로 처리하는 Batch Insert가 필수적입니다. 이 방식은 데이터베이스 I/O를 최소화하여 성능을 향상시킬 수 있습니다.
Batch Insert
여러 개의 INSERT 명령을 단일 SQL 쿼리로 결합함으로써 데이터베이스에 대한 호출 횟수를 줄이고, 네트워크 오버헤드와 데이터베이스 서버의 부하를 감소
Batch Insert를 어떻게 사용하는 지에 따라서도 성능 차이가 발생합니다. 이 부분은 HomoEfficio님의 Spring Data에서 Batch Insert 최적화 글을 참고하시면 좋을 것 같습니다.
@Bean
public JdbcBatchItemWriter<ProductBackup> writer() {
JdbcBatchItemWriter<ProductBackup> writer = new JdbcBatchItemWriter<>();
writer.setDataSource(dataSource);
writer.setSql("INSERT INTO product_backup (name, amount, create_date) VALUES (:name, :amount, :createDate)");
writer.setItemSqlParameterSourceProvider(
item -> new MapSqlParameterSource()
.addValue("name", item.getName())
.addValue("amount", item.getAmount())
.addValue("createDate", item.getCreateDate())
);
return writer;
}총 데이터는 30만개이며 소요시간의 경우 Writer만 변경해서 배치를 실행시킨 결과입니다.
| 처리 방법 | 총 소요시간 |
|---|---|
| JpaItemWriter | 4분 17초 |
| JdbcBatchItemWriter | 3분 42초 |
IN 절 활용
쿼리 IN 절을 사용하여 단일 쿼리 내에서 여러 값을 대상으로 조회하거나 업데이트할 때 데이터베이스의 처리량을 최적화할 수 있습니다.
-- Chunk Size 1000 기준
-- 단일 UPDATE
-- Chunk Size만큼 Database I/O가 발생 (최대 1000번)
UPDATE user SET grade = 'BASIC' WHERE id = 1;
-- ...
UPDATE user SET grade = 'NORMAL' WHERE id = 10;
-- ...
UPDATE user SET grade = 'VIP' WHERE id = 1000;
-- IN UPDATE
-- Chunk Size와 상관없이 최대 3번의 Database I/O가 발생 (최대 3번)
UPDATE user SET grade = 'BASIC' WHERE id in (1, 2, ...);
UPDATE user SET grade = 'NORMAL' WHERE id in (10 11, ...);
UPDATE user SET grade = 'VIP' WHERE id in (500, ...);위 예시와 같이, IN 절을 사용하면 하나의 쿼리로 여러 행을 동시에 처리할 수 있고 복수의 조건을 만족하는 레코드를 효과적으로 필터링하는 데 특히 유용합니다.
JDBC의 ExecuteBatch 활용
그러나 IN 절로 처리하기 어려운 상황이나 대량의 데이터를 다룰 때는 JDBC의 ExecuteBatch를 사용할 수 있습니다. ExecuteBatch는 INSERT, UPDATE, DELETE 등의 다양한 종류의 쿼리를 한 번에 묶어 처리할 수 있습니다.
여러 SQL 명령문을 하나의 배치로 묶어 데이터베이스 서버에 한 번에 전송하고 실행함으로써, 네트워크 지연과 데이터베이스 I/O를 최소화할 수 있습니다. (Chunk Size를 1000으로 설정한 경우, 최대 1000개의 쿼리가 한 번에 묶여서 데이터베이스로 전송되고 실행됩니다)
// Item Writer
public class CustomJdbcBatchItemWriter<T> implements ItemWriter<T> {
private DataSource dataSource;
private String sql;
private BiConsumer<PreparedStatement, T> preparedStatementSetter;
public CustomJdbcBatchItemWriter(DataSource dataSource, String sql,
BiConsumer<PreparedStatement, T> preparedStatementSetter) {
this.dataSource = dataSource;
this.sql = sql;
this.preparedStatementSetter = preparedStatementSetter;
}
@Override
public void write(Chunk<? extends T> chunk) throws Exception {
List<? extends T> items = chunk.getItems();
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
connection = dataSource.getConnection(); // 커넥션 획득
connection.setAutoCommit(false); // 자동 커밋 비활성화
preparedStatement = connection.prepareStatement(this.sql); //sql 로 prepared statement 생성
for (T item : items) {
preparedStatementSetter.accept(preparedStatement, item); // prepared statement에 파라미터 바인딩
preparedStatement.addBatch(); // batch에 prepared statement 추가
}
preparedStatement.executeBatch(); // 배치에 추가된 모든 SQL 문을 데이터베이스에 한 번에 전송
connection.commit(); // 트랜잭션을 커밋
} catch (SQLException e) {
if (connection != null) {
connection.rollback();
}
throw new Exception("Error executing batch write", e);
} finally {
if (preparedStatement != null) {
preparedStatement.close();
}
if (connection != null) {
connection.close();
}
}
}
}// Batch Writer
@Bean
public CustomJdbcBatchItemWriter<ProductBackup> writer() {
String sql = "INSERT INTO product_backup (name, amount, create_date) VALUES (?, ?, ?)";
return new CustomJdbcBatchItemWriter<>(dataSource, sql, (PreparedStatement ps, ProductBackup item) -> {
try {
ps.setString(1, item.getName());
ps.setLong(2, item.getAmount());
ps.setDate(3, Date.valueOf(item.getCreateDate()));
} catch (SQLException e) {
throw new RuntimeException("Error setting PreparedStatement values", e);
}
});
}
Batch Insert와 JDBC의 ExecuteBatch Insert 차이
-
Batch Insert: 한 번에 많은 데이터를 삽입하는 하나의 큰 SQL 문을 작성하여 처리
-
JDBC ExecuteBatch: 여러 개의 작은 INSERT 문을 모아 한 번에 처리하는 방법
명시적으로 쿼리를 구현
성능을 높이기 위해 필요한 컬럼만 업데이트하는 명시적 쿼리를 구현합니다. 필요하지 않은 컬럼을 제외함으로써 데이터베이스 서버 부하와 전송(Fetch) 데이터량을 감소시키며, 네트워크를 통해 전송된 데이터의 객체 변환 처리(Deserialize) 시간도 단축시킬 수 있습니다.
JPA 사용 고민
-
JPA는 편리하고 풀스택 ORM이지만, 복잡성과 불필요한 체크 로직으로 인해 성능 저하를 일으킬 수 있습니다. 배치 처리에서는 Reader와 Writer가 구분되어 있어서 JPA의 영속성 관리와 더티 체킹이 불필요합니다.
-
일부 JPA 구현체는 엔티티를 업데이트할 때 모든 필드를 포함하는 업데이트 쿼리를 생성할 수 있어, 이로 인해 불필요한 데이터베이스 트래픽과 부하가 발생합니다.
-
IDENTITY ID 생성 전략을 사용할 경우, JPA는 각각의 Insert 연산 후 즉시 생성된 ID를 필요로 하므로, 배치 Insert 기능을 지원하지 않습니다.
-
데이터를 읽을 때부터 JPA를 사용하지 않는 것도 성능 최적화를 위한 좋은 방법이 될 수 있습니다.
결론
성능 최적화를 고려할 때, 단계적으로 접근하는 것이 중요합니다.
처음부터 복잡하고 직관적이지 않은 방법을 도입하기보다는 크게 변경하지 않는 선에서 성능 향상을 시도해보는 것이 좋습니다.
그럼에도 불구하고 성능 이슈가 여전히 존재한다면, 단계적으로 한 단계씩 최적화를 진행하여 문제를 해결하는 것이 중요하다고 생각됩니다.
참조
[Data] Batch Performance 극한으로 끌어올리기: 1억 건 데이터 처리를 위한 노력 / if(kakao)dev2022
Spring Batch 애플리케이션 성능 향상을 위한 주요 팁 (김남윤, Yun)